脸部3D模型重建
题目
REAL-TIME 3D FACE MODELING WITH A COMMODITY DEPTH CAMERA
概述
本系统通过记录(registering)和整合(integrating)多个用户头部的深度图来重建高质量的3D脸部模型,通过建立KinectFusion系统,先把分段的深度图像粗糙地记录和整合起来,然后提供一个快速技术,来达到实时运行在普通商用硬件(Kinect)上。
系统概览:
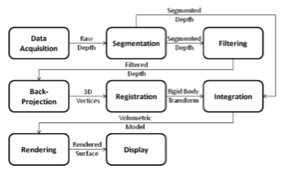
解读:
构建3D人脸模型现在有两种比较主流的方式,一种是使用无源(passive)传感器得到多张2D的图像去重构,还有一种是利用主动式(actor)传感器去直接生成。第二种方法显然在实现上是比较方便的,但是过去因为受限于价格的问题,所以迟迟没有很好的发展。 现在,因为微软有Kinect的发布,所以让普遍地使用第二种方法成为现实。本系统就是建立在Kinect上,采用第二种方法来实现的。
因为Kinect产生的实时的深度图总是有比较多的“噪声”(noise),所以本系统使用了KinectFusion系统,使用户可以在固定得Kinect前只是简单地移动一下头部,就可以帮助生成高质量的3D脸部模型。
论文内容
关于KinectFusion
本系统没有采用一般的模型去生成3D脸部,也没有使用空间滤波去处理噪声。而是采用一种KinectFusion的系统。这种系统本来是用来生成房间大小的3D模型的。具体操作方法是拿着Kinect绕着房间走一圈来生成房间这个环境的3D模型。利用这种思想,本系统稍微做了修改,就是固定住了Kinect,然后让人的头部在Kinect前面移动,达到生成头部模型的效果。
数据采集
利用Kinect采集在拍摄视频速率下的深度信息,每一个时间点都会得到一列数据。
分割
首先假设人是在Kinect的前方,保证坐直的姿势,并且头部和肩膀的部分是清晰可见的,然后根据头部比躯干的宽度要宽的前置条件,从而找到头部的部分。
过滤
使用双边滤波,消除局部方差,对头部周围的信息,例如头发等噪声进行过滤。
反投影(Back-projection)
首先需要创建一个点云的背面投影到三维顶点的深度像素和估计每个顶点的表面法线。然后产生一个顶点地图,通过背面投影到相机的参考帧的每一个深度像素。最后通过交叉乘积估计每个点的表面法向量。
登记(Registration)
确定刚体变换,对每个顶点映射,将顶点和表面法向量生成全局坐标。使用附近点迭代(Iterative closest point)来进行快速生成,但是不可避免地会出现误差,所以使用投影数据关联最小化误差矩阵。
整合
一旦被确定是刚性变化,就可以用卷来表示一个头部,深度图像就可以被整合到三维模型中。该卷包含像素,其中每个像素包含重量和标记距离最近的表面沿照相机射线。
渲染
渲染的卷显示当前状态的模型给用户,这样他们就可以重新定位他们的头部,以增强不同部分模型。此外,使用当前状态的卷来细化顶点地图和法线贴图。更新基于该模型的顶点和法线,提高标记步骤的稳定性。
结果
这个系统出来的效果,可以捕捉到更多的细节,并且基本可以实现实时的显示。可以在实验机器中实现25帧的播放。
心得
这篇论文相对来说写的思路比较清晰一点,而且实现的不会太复杂,做了一个实时的脸部重建。公式之间不会有太复杂的逻辑关系。总体比上一篇好懂很多。
看的两篇都是关于Kinect的研究的,都是三维重建的,觉得可能现在的研究也比较集中在这一块。我的想法是毕业设计做一些看起来比较有交互比较可操作的东西,好玩一点有想法一点的,不要太单纯的理论研究。因为觉得现在研究的话很多论文都研究得非常的深入了,如果再在这上面想要有所突破可能我现阶段的能力还比较有限。所以初步的想法是参照一些论文把一些技术点实现出来,然后在这基础上做一些动作识别之类的转化为比较可用实用的应用。
和师兄交流之后,感觉基于Kinect如果要有一些深入的开发的话,可能还会不可避免地涉及到一些模式识别的知识。所以可能自己还要补充一点相关的知识,不能像现在的知识面这么窄来思考问题。