手绘草图
题目
Offline Sketch Parsing via Shapeness Estimation
概述
这篇论文的主题十分有趣,是进行一个将手画的草图解析为计算机中流程图的方法。而且相对于现有的类似的方法,它进行了一些很必要的改进。
- 进行了shapeness estimation(注:Shapeness这个词在各大词典上面都搜不到相关的释义,我在这里及下文把它翻译为“形变”,可能不太准确),从而把候选组的个数从几千大大降低到只有几十。
- 提出了三级级联框架(three-stage cascade framework),进行脱机的素描解析,降低错误率。
文章反复说明的一个说明结果的例子:仅用32个候选组的情况下(注:之前的工作通常都是几千),达到96.2%的检出率(注:应该就是正确率)
下图是作者展示的成果,这效果着实被惊艳到!
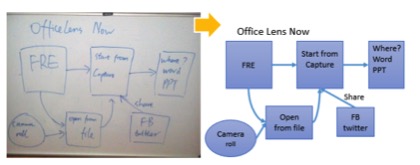
论文内容
主要步骤
文中提出了一个用于脱机素描解析的框架,使用选择识别的策略。
三级级联框架:
-
形变估计
-
形状识别
-
利用素描领域的知识解析
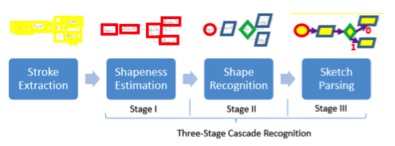
其中的形变估计:
-
1.1 首先检测少量的stroke groups(注:这个也不知道怎么样比较准确地翻译它,暂且称之为“笔画组”,感觉差不多是这个意思),快速找到好的形状并识别出这些组。
-
1.2 将这些有良好封闭性的手绘形状归一化成非常小的尺寸,来识别他们的形状。
-
1.3 使用“形变估计”算法的评分(shapeness estimation,好吧我承认这个词我翻译得比较失败,还是稍微标一下原文避免误会)来估计这个“笔画组”是不是一个好的形状。
-
1.4 为了加快“形变估计”,引入紧凑而有效的特征值来表示每一个“笔画组”。
-
1.5 为了加快特征值的提取,避免重复操作,文章又提出了一个预处理,来计算每个笔画中的主要信息。
-
1.6 进行预操作,计算特征值,避免频繁重复提取特征值。
形变估计(shapeness estimation)
我们给出的笔划提取图像集合。
-
生成候选笔画组:图像的N条描边,将2N可能的组。我们利用空间的约束,以减少搜索空间。
-
压缩 INT64 特征值表示:1) 处理笔画级别变化的手绘形状,2) 方便快速的特征提取。
-
快速特征值提取:为相关群体特征提取时,尽可能多地避免重复对相同笔画的操作。
-
学习形变测量:学习一个线性模型,使用线性SVM,保留与得分最高的笔画组数目:
形状识别(Shape Recognition)
利用一种更准确的孤立的素描识别算法来预测形状类型。可以在这里使用一些良好执行的分类器来识别手绘制的形状。论文中采用了1NN分类器,使用原始的 720 视觉功能。每个组得分为特征向量输入的形状和中训练集的形状之间的距离。计算每个组的得分后,将这些组得分进行排序,随后进行非最大抑制 (NMS)。如果为达到以下条件,将这个组删除:
-
它与一个笔画组共享相同的笔画,并且另外一个具有较好 (较小) 的评分
-
其定界框完全包含,或被一个具有较高 (较小) 评分的笔画组完全包含。
下图为形变估计和形状识别的效果图:
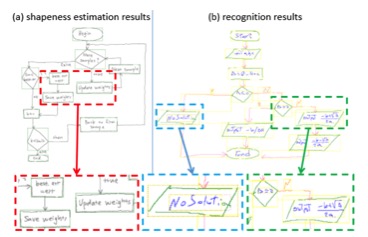
利用领域知识进行素描解析(Sketch Parsing using Domain Knowledge)
-
将识别到的形状中的文字进行分组:使用格雷厄姆扫描算法,为每个识别后的形状计算凸壳。然后,在凸壳内的笔画组合在一起。手写的文字识别算法可以用于进一步分析的分组的笔触。
-
识别连接器:使用深度优先算法(DFS),从每一个形状出发,判断两个不同的形状中间是否有连接,并且确定是连线还是箭头。
-
将其余的笔画进行分组:识别出形状,连接器和形状中的文本后,我们继续将其余的笔画作为嘈杂笔画或其他种类的模式进行分组操作。
实验结果
与其他方法进行对比之下,论文中采用的方法在准确性上优势明显
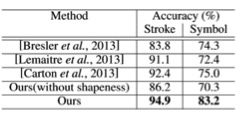
而且同时,效率上也有这比较大的优势。就像本文一直强调的,仅用了32个候选组,就达到了96.2%的准确率。
心得
这星期看得这篇论文是高老师之前分享在群里的一篇非常有趣的论文。这是看了这几篇论文以来最让我着迷的一篇论文了。
它不会很单纯地秀一些底层的算法和优化逻辑,而是真真切切地用算法的方式,创新的思维来解决一个现实中的问题。如果论文中的这种方法得到推广,直接可以手画流程图就直接转化在计算机里面,这将是非常好的体验!
附:Kinect学习小记
正如微软文档里面自己说的一样,最快捷的方式,就是直接调用它的接口,这一点说得虽然很打击开发者的自信心,不过也真的很有道理。这几个星期看了关于Kinect SDK的东西,当然也看了一些周边的东西例如openni。感觉微软的SDK确实有它的过人之处。
例如有人在博客上用openni实现的一个把人物像抠出来,然后把背景换掉的功能,我试用了一下,虽然在我的机子上面跑还不至于崩溃,但是帧数就十分有限,显得有一点卡顿,而且边缘也没有处理得比较精细,看它实现的过程已经比较复杂了。但是用微软的SDK直接调用它,出来的效果就比较理想了,帧数也多而且边缘的细节出来的都比较好。
其实实现出来这个在有SDK的前提下就变得不太困难了。只需要调用SDK中的对于锁定的深度图像的检测,然后对于图像中发生变化的图像进行对背景的替换就可以了。调用的方式如下:
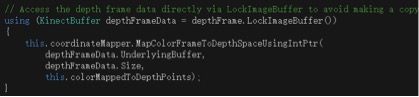
十分简洁地就利用到了Kinect SDK的属性。而且这个效果可能是微软在代码上面做了很多的优化,所以运行起来的效果比网上很多论坛上面提供的开源代码的效果要好很多。而接下来就只需要对于抓取到的不固定的图像的位置进行替换,进行对应的关系,然后把背景图的颜色信息替换为摄像机拍摄的像素信息。
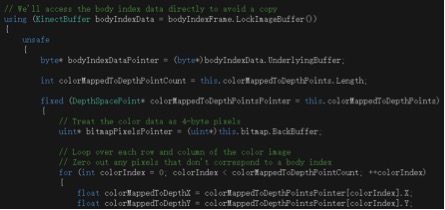
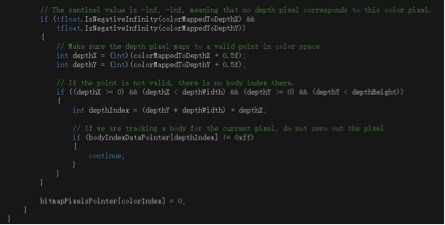
体会到了SDK调用的优越性之后,下周打算把里面给的sample的代码都自己手动得改一改,调一调参数,更加详细地了解一下里面调用的具体方法。争取接下来的几周能够在这几个sample还有师兄给的一些博客资源中,找到可以给我之前的想法搭建一个基本框架的东西,实现最基本的功能。然后再在这个环境中间部署一些纹理和模型的图形。
虽然说直接调用SDK的代码还是比较容易看懂的,但是当自己真正下手改的时候还是发现有很多关联的逻辑关系会出错,可能自己还没有真正的把这些实现弄明白吧。接下来可能可以尝试一下更大的改动,甚至是把两个功能合在一起试一下看看有什么效果。可能会对自己的理解比较大帮助。
其他
感觉自己之前看论文的时候可能更多的在周报里面讲的是自己对论文看完之后的一些理解。和同学交流了一下,觉得可能这种理解可以更加深层一些,不单停留在字面上,可能自己也可以提出一些质疑,一些疑问,甚至一些反驳。周报确实是一种很好的东西,写给老师,其实也是写给自己。也许这些质疑或者反驳不一定正确,但是它可能更能带动我的思考,把问题和自己的思考都记录下来,也许学到的东西更多了的时候,返回来看,可能就会又有不同的理解和看法了。